
归纳总结材料:DeepMind新方法JEST提升AI训练
主要成就
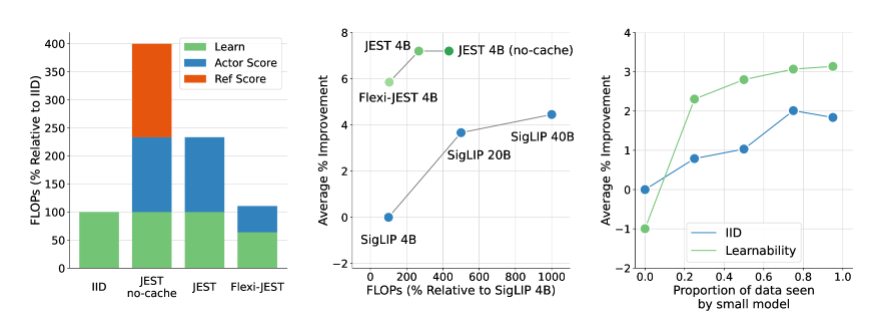
- 训练时间减少13倍:DeepMind的JEST方法极大地缩短了AI训练所需的时间。
- 算力需求降低90%:通过优化数据筛选和训练方式,显著减少了计算资源的消耗。
JEST方法的核心创新
- 数据批次筛选:与传统的单个样本筛选不同,JEST通过联合选择最佳数据批次进行训练,提高了多模态学习的效率。
- 在线模型近似:使用在线模型的近似来高效过滤数据,进一步提高训练效率。
- 小型高质量数据集引导:结合小型高质量数据集和更大的非精选数据集,优化了预训练数据分布及模型泛化能力。
工作原理
- RHO损失评估:结合学习模型和预训练参考模型的损失,评估数据点的可学习性,选择那些对预训练模型容易但对当前学习模型较难的数据点。
- 阻塞吉布斯采样:通过迭代方式逐步构建批次,每次迭代根据条件可学习性评分选择新的样本子集,不断改进数据过滤过程。
关键结论
- 最佳数据批次选择优于单个数据点挑选。
- 在线模型近似用于高效数据过滤。
- 利用小型高质量数据集引导大规模非精选数据集。
未来展望
- 突破性进展:JEST方法为AI训练领域带来了革命性的变革。
- 广阔前景:随着JEST的进一步优化和应用,AI技术的发展将迎来更加光明的未来。
参考论文
划重点
- 训练效率革命:DeepMind的JEST方法使AI训练时间减少13倍,算力需求降低90%。
- 数据批次筛选:JEST通过联合选择最佳数据批次,而非单个样本,显著提升了多模态学习的效率。
- 创新训练方法:JEST利用在线模型近似和高质量数据集引导,优化了大规模预训练的数据分布和模型泛化能力。
这份材料显示了DeepMind在AI训练效率上的重大突破,这一研究成果不仅能加速AI模型的开发周期,还能节省大量计算资源,对公司的研发和运营具有重要意义。
